"在當今這個數字化時代,數據安全不僅是保護個人隱私和企業機密的基石,也是維護社會信任和經濟穩定的關鍵。"
什麼是哈希值?
哈希值是由哈希函數從任意大小的輸入數據生成的固定大小的字符串或數字。這些函數接受不同的輸入,如文本、圖像和視頻,產生一個固定長度、不可逆的哈希值。哈希值是確定性的,意味著相同的輸入總是產生相同的輸出。它們還具有碰撞阻力,使得找到產生相同輸出的不同輸入變得具有挑戰性。
哈希值的功能
哈希值在計算機科學和IT領域扮演著重要的角色,提供了一個固定長度的數據摘要,不論數據大小。這些功能促進了各種應用:
- 數據完整性驗證:用於檢查數據在傳輸過程中是否保持不變,確保下載文件的完整性。
- 密碼存儲:出於安全考慮,密碼以哈希值形式存儲,使得從被洩露的數據庫中恢復原始密碼變得困難。
- 快速數據檢索:哈希值在哈希表中充當索引,允許高效的數據操作。
- 數據去重:通過比較哈希值幫助識別並刪除重複的數據項。
- 數字簽名和驗證:通過公鑰密碼學和哈希函數確保數據的完整性和來源。
- 區塊鏈技術:利用哈希值來保護交易記錄並確保數據的不可篡改性。
- 防篡改時間戳:為數據提供不可逆的時間戳,用於法律和版權保護。
哈希值在這些領域有效的原因是由於它們的關鍵特性:速度、確定性、不可逆性和碰撞阻力。正確使用時,哈希函數可以在保護數據、提高效率和驗證信息的真實性方面提供強大的支持。
什麼是哈希函數?
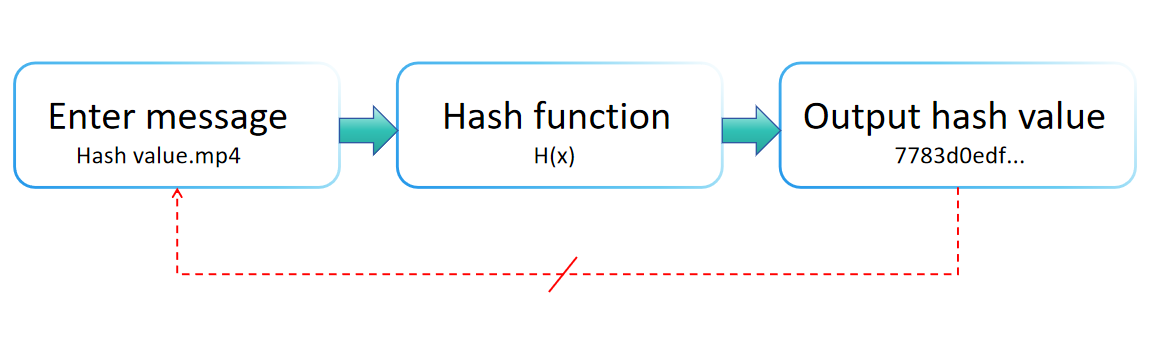
哈希函數是一種將輸入數據(或“消息”)映射到固定大小字符串的數學結構,通常是一個數值,如下圖所示。哈希函數在數據管理和信息安全中被廣泛使用,其特點是計算效率高、輸出長度一致、不可逆、對輸入變化敏感以及具有碰撞阻力。

高效的計算性能
哈希函數可以快速地從任何形式的數據計算出哈希值,無論數據的大小。這一特性對於需要快速訪問數據的應用至關重要,例如哈希表。這是因為在哈希表中存儲數據時,哈希函數的速度決定了數據檢索的速度。哈希表使用哈希函數快速定位數據的存儲位置,依賴哈希函數的快速計算能力。
此外,在需要處理大量數據的系統中,哈希函數的效率直接影響整個系統的性能。如果哈希函數運行緩慢,它將成為系統性能的瓶頸。一些實時系統,如網絡設備中的數據包過濾,需要立即計算數據的哈希值以做出快速決策。在這些情況下,哈希函數的效率同樣至關重要。
例如,考慮一個在線電子商務平台,用戶可能在搜索欄中輸入產品名稱以查找產品。後端系統可能使用哈希函數快速定位存儲在哈希表中的產品信息。如果哈希函數的計算過程慢,用戶體驗將嚴重受影響,因為他們將不得不等待更長時間才能獲得搜索結果。在這種情況下,哈希函數的高效計算性能確保了快速的響應時間,從而改善用戶體驗。 [了解更多]
哈希函數中的輸出長度一致性
哈希函數將任意長度的輸入轉換為固定長度的輸出,通過複雜的計算系列過程實現。這個過程通常涉及將輸入數據分成固定大小的塊(對於超過處理單元大小的輸入),對每個塊應用一系列數學和邏輯操作,然後以某種方式組合或累積這些操作的結果,最終產生固定大小的哈希值。
為什麼這很重要? 輸出長度的一致性有助於確保哈希函數的安全性。如果哈希輸出的長度可能變化,它可能會洩露有關原始數據大小的信息,這可能在某些情況下被利用來攻擊系統。此外,固定輸出長度也使攻擊者難以通過分析輸出長度來推斷輸入數據的特徵。同時,固定長度的輸出簡化了哈希值的存儲和比較。系統設計者可以提前知道每個哈希值將佔用多少空間,這對於數據庫設計和網絡傳輸等場景非常重要。此外,輸出長度的一致性使得比較哈希值是否相等變得非常高效,因為它只需要比較固定長度的數據。這在使用哈希表進行快速數據檢索時尤其重要。
以SHA-256為例,這種廣泛使用的加密哈希函數無論輸入數據是單個字節還是幾百萬字節,總是產生一個256位(即32字節)的哈希值。這種一致性確保SHA-256哈希值可以用於各種安全應用,如數字簽名和消息認證碼(MACs),同時簡化了數據處理和存儲工作流程。
哈希函數的不可逆性
哈希函數是單向的,這意味著從哈希值無法推斷出原始數據。這一特性在存儲密碼時尤其重要,因為即使數據庫被破壞,攻擊者也無法從哈希值恢復密碼。哈希函數的不可逆性主要基於以下原則和特性:
- 壓縮:哈希函數可以將任何長度的輸入(在實際使用中可能非常大)映射到固定長度的輸出。這意味著有無限多個可能的輸入被映射到有限數量的輸出。由於輸出空間(哈希值)遠小於輸入空間,不同的輸入將不可避免地產生相同的輸出,這種現象稱為“碰撞”。由於這種壓縮,不可能從給定的輸出(哈希值)確定特定的輸入。
- 高非線性和複雜性:哈希函數設計時使用複雜的數學和邏輯操作(如位運算、模運算等),以確保輸出對輸入高度敏感。即使對輸入(例如,改變一個位)進行微小的更改,也會導致輸出(哈希值)的顯著和不可預測的變化。這種高度的非線性和輸出的隨機性使得從哈希值推斷原始輸入極為困難。
- 單向性:哈希函數的設計確保了其操作是單向的;即計算哈希值很容易,而反向過程(從哈希值恢復原始數據)不可行。這是因為哈希函數的計算過程涉及一系列不可逆的操作(如模運算的不可逆性),確保即使有哈希值,也不可能逆向工程原始數據。
- 隨機映射:理想的哈希函數應該充當“隨機映射器”,意味著每個可能的輸入都同樣可能被映射到輸出空間中的任何點。這一屬性確保沒有可行的方法預測特定輸入將映射到哪個輸出,增強了哈希函數的不可逆性。
- 數學基礎:從數學上講,哈希函數的不可逆性可以通過它們依賴的“離散對數問題”、“大整數因式分解問題”或其他難以用當前數學和計算能力解決的數論問題來理解。例如,某些哈希算法的設計可能間接依賴於這些問題的計算難度,從而確保它們的不可逆性。
輸入敏感性和雪崩效應
在哈希函數的設計中,利用複雜的數學和邏輯運算(如位運算、模運算等)確保輸出對輸入高度敏感。即使對輸入(例如,改變單個位)的微小更改都會導致輸出(哈希值)的顯著和不可預測的變化,這種現象稱為“雪崩效應”。 [了解更多]
密碼學中的碰撞阻力
哈希函數的碰撞阻力是密碼學中的一個關鍵概念,它指出了哈希函數抵抗碰撞攻擊的安全級別。這個屬性意味著對於任何哈希函數H,找到兩個不同的輸入x和y(x ≠ y)使得H(x) = H(y)在計算上是不可行的。具有強大碰撞阻力的哈希函數使得找到兩個不同的輸入產生相同輸出值變得極其困難。
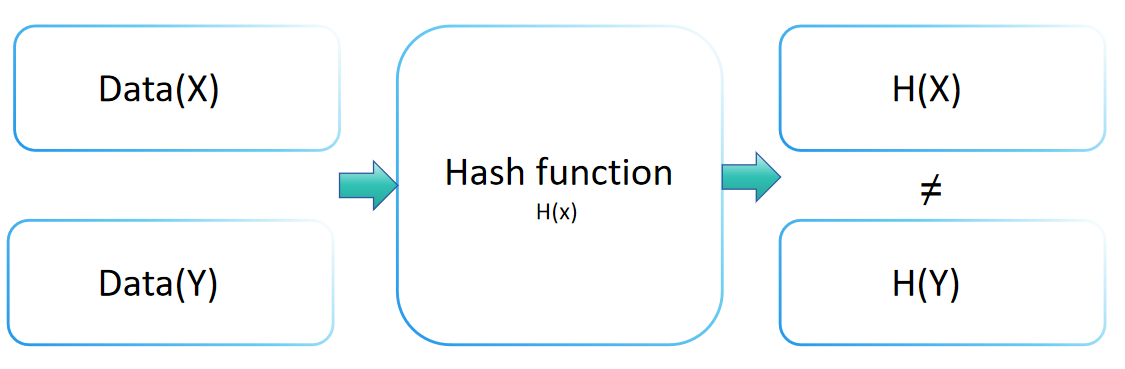
碰撞阻力在維護數據完整性和驗證中發揮著至關重要的作用。通過將輸入信息轉換為固定大小的輸出(或摘要),哈希函數確保沒有兩個不同的輸入產生相同的輸出。這一獨特特性允許哈希值準確識別原始值。
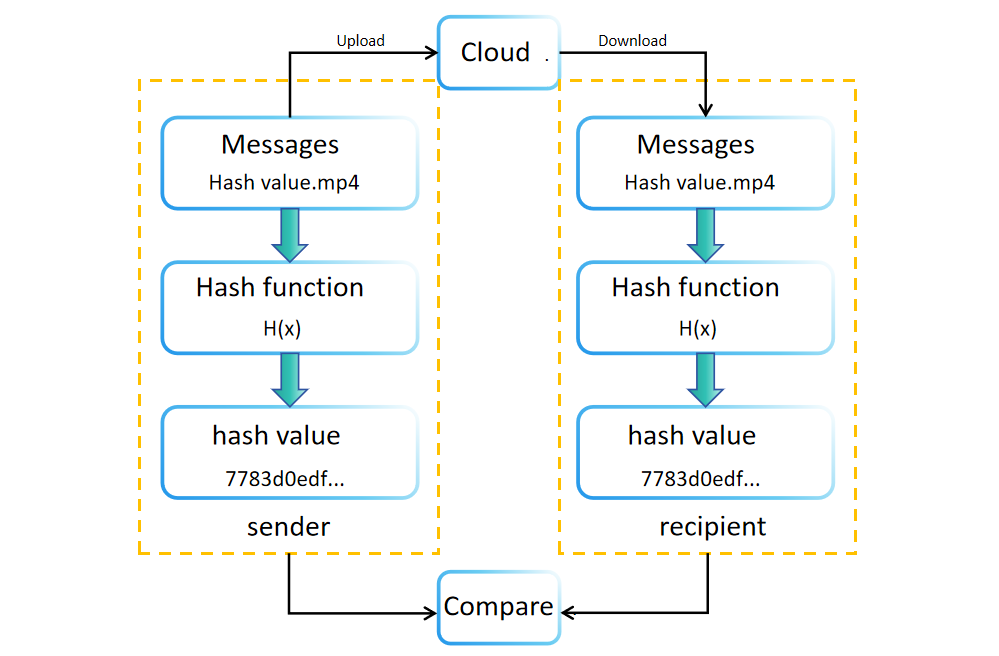
在數據創建或存儲期間,使用哈希函數生成一個哈希值(或摘要)。這個值與原始數據一起存儲或傳輸。例如,軟件下載網站經常顯示文件哈希值以進行完整性驗證。接收者可以獨立重新計算收到的數據的哈希值以確認其完整性。如果原始哈希值和重新計算的哈希值匹配,則驗證了數據的完整性。如果不匹配,數據可能在傳輸或存儲過程中被篡改或損壞。
比較哈希值還具有驗證數據完整性的優勢,而無需占用大量存儲空間。這種方法允許接收者通過簡單地比較傳輸前後的哈希值來確認數據的真實性。
哈希碰撞能被找到嗎?
通過上述提到的哈希函數的特性,我們已經了解了碰撞阻力。但是,哈希碰撞是否可能存在,即兩個不同的輸入產生相同的輸出呢?答案是肯定的,碰撞確實存在。根據抽屜原理,只要輸入空間足夠大,就有可能發生哈希碰撞。這是因為哈希函數的輸出空間通常遠小於輸入空間,不可避免地導致多個不同的輸入映射到同一個輸出。
抽屜原理是組合數學中一個簡單直觀的原理,它表明如果將超過n個對象放入n個容器中,則至少有一個容器將包含兩個或更多對象。這個原理也可以用來解釋諸如生日悖論等問題。
抽屜原理的應用非常廣泛,在密碼學、計算機科學和數學等領域都有重要用途。例如,在計算機科學中,抽屜原理用於證明某些算法的正確性或分析算法的時間複雜度。在密碼學中,抽屜原理也用於設計特定的密碼攻擊方法,如生日攻擊。
生日悖論是抽屜原理的一個經典應用。假設有n個人在一個房間裡。如果我們希望至少兩個人共享相同生日的概率大於50%,需要多少人?根據抽屜原理,如果將367個人(假設一年有366天,加上閏年的2月29日)放入366個“抽屜”(即生日)中,則至少有一個“抽屜”將包含兩個人,意味著至少有兩個人共享相同的生日。這說明了生日悖論。
需要注意的是,儘管抽屜原理簡單直觀,但其應用必須考慮具體的上下文。例如,在應用抽屜原理時,有必要確保所涉及的隨機變量彼此獨立;否則,可能會導致錯誤的結論。此外,在某些情況下,也需要考慮抽屜的大小和形狀等因素。
然而,僅僅通過遍歷輸入空間來嘗試尋找哈希碰撞可能不切實際,主要有兩個原因:
- 計算複雜性:對於大多數哈希函數,輸入空間是巨大的。以SHA-256為例;其輸出是一個256位的哈希值,這意味著它有2^256個可能的輸出。由於哈希函數的設計目標之一是盡可能最小化碰撞,理論上,根據生日悖論,找到SHA-256的哈希碰撞需要遍歷大約2^(256/2) = 2^128個輸入,這是找到碰撞所需的預期輸入數量。即使使用目前最強大的超級計算機,完成這樣的任務也遠遠超出人類壽命。因此認為通過簡單遍歷找到SHA-256哈希碰撞是不可能的。
- 哈希函數的設計:哈希函數通常被設計為使找到碰撞在計算上不可行。這意味著,儘管理論上存在碰撞,但在實踐中實際上不可能找到。這是密碼哈希函數(如SHA-256)的一個重要特性,這些函數廣泛用於數字簽名、密碼存儲等領域。
當然,我們也可以使用特定的算法嘗試找到哈希碰撞。這些算法通常利用哈希函數的一些已知屬性或弱點來找到碰撞。以下是一些常見的技術和方法用於尋找哈希碰撞:
- 生日攻擊:這是一種基於概率的簡單方法,用於估計隨機選擇輸入時找到碰撞所需的時間。生日攻擊的原理是,如果房間裡有很多人,兩個人擁有相同生日的概率隨著人數的增加而增加。類似地,在哈希函數中,如果隨機選擇足夠數量的輸入,最終可能有兩個輸入產生相同的哈希輸出。
- 暴力攻擊:這是最直接的方法,涉及遍歷所有可能的輸入以找到碰撞。然而,由於需要巨大的計算資源和時間,這種方法對於具有大型輸入空間的哈希函數來說不切實際。
- 彩虹表:這種技術用於預先計算和存儲大量的哈希值及其對應的輸入。彩虹表對於破解沒有使用隨機數據混淆或已知哈希函數的密碼特別有用。通過在彩虹表中查找,攻擊者可以快速找到與特定哈希值匹配的輸入。
- 哈希擴展攻擊:某些哈希函數允許攻擊者在不知道原始輸入的情況下將額外數據與已知哈希值結合,從而生成新的哈希值。這種攻擊可用於構造碰撞或執行其他類型的攻擊。
- 特別構造的輸入:有時,攻擊者可以利用哈希函數的特定弱點或非線性行為來構造更有可能在哈希函數中產生碰撞的特殊輸入。
常用的哈希函數有哪些?
MD5(消息摘要算法5)
MD5是一種廣泛使用的加密哈希函數,由Ronald Rivest在1990年代設計,用以取代較舊的MD4算法。它可以將任意長度的消息轉換為固定長度的哈希值(128位,或16字節)。MD5的設計目標是提供一種快速且相對安全的方式來生成數據的數字指紋。然而,MD5的碰撞方法已被發現,使得該算法不再安全,但在安全性不是主要關注點的情況下仍被廣泛使用。
MD5的計算過程涉及以下步驟:
- 填充:初始時,原始數據被填充,使其字節長度是512的倍數。填充以1開始,後跟0,直到滿足長度要求。
- 添加長度:將一個64位長度值(即原始消息長度的二進制表示)添加到填充消息中,使最終消息長度為512位的倍數。
- 初始化MD緩衝區:初始化四個32位寄存器(A、B、C、D)以存儲中間和最終哈希值。
- 處理消息塊:填充並處理長度的消息被分割成512位的塊,並且每個塊通過四輪操作進行處理。每輪包括基於非線性函數(F、G、H、I)、左循環移位操作和模32加法的16個類似操作。
- 輸出:最終哈希值是四個寄存器A、B、C、D的最後狀態連在一起的內容(每個寄存器是32位),形成128位的哈希值。
SHA-1(安全哈希算法-1)
SHA-1由美國國家安全局(NSA)設計,並於1995年由國家標準技術研究院(NIST)發布為聯邦信息處理標準(FIPS PUB 180-1)。SHA-1旨在用於數位簽名和其他密碼學應用,生成一個160位(20字節)的哈希值,稱為消息摘要。儘管現在已知SHA-1存在安全漏洞,並已被更安全的算法如SHA-256和SHA-3取代,但理解其工作原理仍具有教育和歷史價值。
SHA-1的設計目的是接收任意長度的消息並產生一個160位的消息摘要,以驗證數據的完整性。其計算過程可以分為以下步驟:
- 填充:最初,原始消息被填充,使其長度(以位為單位)模512等於448。填充始終以“1”位開始,後跟若干個“0”位,直到滿足上述長度條件。
- 添加長度:向填充消息中添加一個64位塊,表示原始消息的長度(以位為單位),使最終消息長度為512位的倍數。
- 初始化緩衝區:SHA-1演算法使用一個160位緩衝區,分為五個32位寄存器(A、B、C、D、E),用於存儲中間和最終哈希值。這些寄存器在演算法開始時初始化為特定的常數值。
- 處理消息塊:預處理的消息被分割成512位塊。對於每個塊,演算法執行包含80個類似步驟的主循環。這80步分為四輪,每輪20步。每一步使用不同的非線性函數(F、G、H、I)和常數(K)。這些函數旨在增加操作的複雜性和安全性。在這些步驟中,演算法使用位運算(如AND、OR、XOR、NOT)和模32加法,以及左循環移位。
- 輸出:處理所有塊後,五個寄存器中累積的值被連接起來,形成最終的160位哈希值。
SHA-2(安全哈希算法-2)
SHA-2 是一系列密碼哈希函數的集合,包括幾個不同的版本,主要由六種變體組成:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224和SHA-512/256。SHA-2由美國國家安全局(NSA)設計,並由國家標準與技術研究院(NIST)發布為聯邦信息處理標準(FIPS)。與其前身SHA-1相比,SHA-2提供了增強的安全性,主要體現在更長的哈希值和更強的碰撞阻力上。
SHA-2 家族的運作在許多方面類似於SHA-1,但通過使用更長的哈希值和更複雜的處理程序提供更高的安全性。以下是SHA-2演算法的主要步驟:
- 填充: 輸入消息首先被填充,使其長度減去64位後等於448或896,基於模512(對於SHA-224和SHA-256)或模1024(對於SHA-384和SHA-512)的基礎。填充方法與SHA-1相同,涉及在消息末尾添加“1”,隨後是若干個“0”,最後是原始消息長度的64位(對於SHA-224和SHA-256)或128位(對於SHA-384和SHA-512)二進位表示。
- 初始化緩衝區: SHA-2演算法使用一組初始化的哈希值作為開始緩衝區,具體取決於所選的SHA-2變體。例如,SHA-256使用八個32位寄存器,而SHA-512使用八個64位寄存器。這些寄存器初始化為特定的常數值。
- 處理消息塊: 填充的消息被劃分為512位或1024位的塊,每個塊經歷多輪密碼學操作。SHA-256和SHA-224執行64輪操作,而SHA-512、SHA-384、SHA-512/224和SHA-512/256執行80輪。每輪操作包括一系列複雜的位運算,包括邏輯、模加和條件操作,依賴於不同的非線性函數和預定義常數。這些操作增加了演算法的複雜性和安全性。
- 輸出: 最終,在處理所有塊之後,緩衝區中的值被組合形成最終的哈希值。根據SHA-2變體,這個哈希值可以是224、256、384或512位長。
你可能好奇為什麼哈希函數的輸入可以是任意長度,但輸出是固定的。原因是SHA-2家族使用了Merkle-Damgård變換,它允許從固定長度的壓縮函數構建可以處理任意長度消息的哈希函數。Merkle-Damgård變換被許多傳統哈希函數採用,包括MD5和SHA-1。
Merkle-Damgård變換的核心思想是將輸入消息劃分為固定大小的塊,然後逐個處理這些塊,每個處理步驟都依賴於前一個的結果,最終產生固定大小的哈希值。SHA-256的填充步驟體現了Merkle-Damgård變換的基本原則,即通過適當的填充來處理任意長度的消息,並確保最終處理的消息長度滿足特定條件(例如是固定長度的倍數)。因此,可以說SHA-256的填充步驟遵循Merkle-Damgård變換方法。
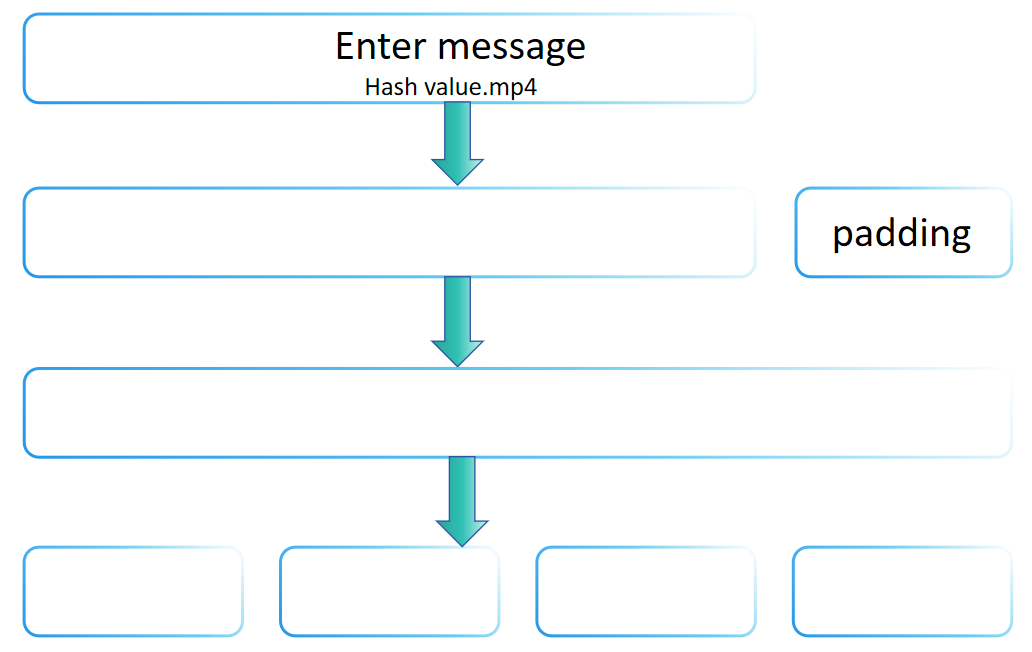
然而,SHA-256並不僅僅是Merkle-Damgård變換的直接實現。它還包括一系列複雜的計算步驟(如消息擴展、多輪壓縮函數等),這些都是SHA-256的獨特設計,旨在增強其安全性。因此,雖然SHA-256在其填充步驟中遵循Merkle-Damgård變換的原則,但通過引入其他安全機制,它增強了整體安全性,使其不僅僅局限於Merkle-Damgård變換的基本框架。
SHA-3(安全哈希算法-3)
SHA-3是最新的安全哈希標準,於2015年由國家標準技術研究院(NIST)正式批准為聯邦信息處理標準(FIPS 202)。SHA-3並不意在取代之前的SHA-1或SHA-2(因為SHA-2仍被認為是安全的),而是作為SHA家族內的一個補充和替代選項,提供一種不同的密碼哈希演算法。SHA-3基於Guido Bertoni等人設計的Keccak算法,並且是NIST在2012年舉辦的SHA-3競賽的獲勝者。
SHA-3的工作原理與SHA-2有很大不同,主要是因為它採用了一種稱為“海綿結構”的方法來吸收和擠壓數據,產生最終的哈希值。這種方法使得SHA-3能夠靈活地輸出不同長度的哈希值,因此比SHA-2提供了更廣泛的應用範圍。SHA-3的主要步驟如下:
吸收階段:
在吸收階段,海綿結構首先將輸入數據分割成固定大小的塊。這些數據塊被順序地“吸收”進海綿的內部狀態中,該狀態通常比單個數據塊要大,以確保可以處理大量數據而不會溢出。具體來說,每個數據塊以某種方式(例如通過異或操作)與內部狀態的一部分合併,隨後應用一個固定的置換函數(在SHA-3中,這是Keccak-f)來轉換整個狀態,從而防止不同輸入數據塊之間的干擾。這個過程重複進行,直到所有輸入數據塊都被處理完畢。
Keccak-f 是 SHA-3 加密哈希演算法中使用的核心置換函數。它是 Keccak 演算法家族的中心組成部分。SHA-3 基於 Keccak 演算法,該演算法贏得了由 NIST 舉辦的加密哈希演算法競賽,並被選為 SHA-3 的標準。Keccak-f 函數有幾個變體,其中最常用的是 Keccak-f[1600],其中的數字表示它操作的位寬。
Keccak-f由多輪相同的操作(稱為輪)組成。對於Keccak-f[1600],總共進行24輪操作。每一輪都包含五個基本步驟: θ(Theta)、ρ(Rho)、π(Pi)、χ(Chi)和ι(Iota)。這些步驟共同作用於狀態陣列,逐步變換其內容,增加混淆和擴散,以提高安全性。下面是這些步驟的簡要說明:
- θ(Theta)步驟: 對每一列的所有位進行XOR操作,然後將結果XOR到相鄰列,以提供列與列之間的擴散。
- ρ(Rho)步驟: 位級旋轉操作,每個位根據預定的規則旋轉不同的位數,這增加了數據的複雜性。
- π(Pi)步驟: 重新排列狀態陣列中的位,改變位的位置,以實現跨行和跨列的擴散。
- χ(Chi)步驟: 非線性步驟,對每一行的每個位進行XOR操作,包括它自己、它的直接鄰居以及鄰居的補碼。這是一個局部操作,增加了密碼算法的非線性特性。
- ι(Iota)步驟: 向狀態陣列的一部分加入輪常數,這個常數每一輪都不同,目的是避免所有輪操作完全相同,引入不可預測性。
Keccak-f通過這些步驟提供了高度的安全性。其設計確保了即使是微小的輸入變化,也會導致狀態陣列中廣泛且不可預測的變化,這是通過混淆(使攻擊者難以從輸出推斷輸入)和擴散(輸入的微小變化會影響輸出的多個部分)原則實現的。
Keccak-f的設計允許在不同的安全級別和應用場景中調整參數(如狀態大小和輪數),提供了極大的靈活性。Keccak-f[1600]以其高效的實現而聞名,無論是在硬件還是在軟件中,都能達到高效的處理速度,特別是在處理大量數據時。
擠壓階段:
一旦所有輸入數據塊都被吸收進內部狀態後,海綿結構進入擠壓階段。在這個階段,內部狀態的部分逐步作為哈希函數的結果輸出。如果所需的輸出長度超過了一次可以擠出的量,海綿結構會再次應用置換函數來轉換內部狀態,然後繼續輸出更多數據。這個過程持續進行,直到達到所需的輸出長度。
SHA-3的設計目標是提供比SHA-2更高的安全性和更好的抵抗量子計算攻擊的能力。得益於其獨特的海綿結構,SHA-3理論上能夠抵禦所有當前已知的密碼攻擊方法,包括碰撞攻擊、原像攻擊和次原像攻擊。
RIPEMD-160(RACE 完整性基元評估消息摘要)
RIPEMD-160是一個旨在提供安全哈希算法的密碼哈希函數。它由Hans Dobbertin等人於1996年開發,是RIPEMD(RACE 完整性基元評估消息摘要)家族的一部分。
RIPEMD-160產生一個160位(20字節)的哈希值,這也是其名稱中“160”的來源。它基於MD4的設計,並受到MD5和SHA-1等其他哈希算法的影響。RIPEMD-160包括兩個並行的、相似的操作,它們分別處理輸入數據,然後將這兩個過程的結果結合起來生成最終的哈希值。這種設計旨在增強安全性。
RIPEMD-160的計算過程包括幾個基本步驟:填充、塊處理和壓縮:
- 填充:首先對輸入消息進行填充,以確保其長度模512位等於448位。填充始終以一個1位開始,後跟一系列0位,最後以原始消息長度的64位表示結束。
- 塊處理:填充後的消息被劃分為512位的塊。
- 初始化:使用五個32位寄存器(A、B、C、D、E),這些寄存器初始化為特定的值。
- 壓縮函數:依次處理每個塊,通過一系列複雜的操作更新這五個寄存器的值。這個過程包括位運算(如加法、與、或、非、循環左移)以及一組固定的常數的使用。
- 輸出:所有塊處理完畢後,這五個寄存器的值被連接起來形成最終的160位哈希值。